
We learn many lessons from the hyperscalers and HPC centers of the world, and one of them is that those who control their software control their own destiny.
And that’s exactly why all the big hyperscalers, who want to sell AI services or incorporate them into existing services to keep their products against fierce competition, have their own models. Some, more than one, and despite all the formal service, are reluctant to open source the core models they’ve developed over the last few years. To be fair, Meta Platforms is said to be considering a commercial variant of its LLaMA base model, which we detailed in February.
Inflection AI, the startup behind personal intelligence chatbot service Pi, has raised $1.53 billion in venture capital and will eventually spend much of that money on AI training capabilities for CoreWeave, an AI cloud computing provider. and its partner, Nvidia. The company’s Inflection-1 LLM was trained on 3,500 Nvidia Hopper H100 GPUs as part of its recent MLPerf benchmark tests, and we think many thousands of Nvidia GPUs were added to train the full Inflection-1 model.
What we do know is that Nvidia and CoreWeave are building a cloud cluster with 22,000 H100s, which presumably will be used to build and train Inflection-2 LLM. Hardware costs for this machine alone, we calculated, would cost somewhere around $1.35 billion, a bit more than we think Microsoft is shelling out to build a cluster with 25,000 GPUs to train what we assume is the model. GPT-5 from partner OpenAI. (We compared these machines to the El Capitan supercomputer recently built by Hewlett Packard Enterprise and AMD for the Lawrence Livermore National Laboratory in terms of price and various types of performance.) Let’s just say the US government is getting a great deal for the its exascale systems, and we don’t think AI startups or Microsoft can brag about it. The demand is too high and the supply is too low for GPUs for commercial entities not to pay a high premium.
After a deep dive into Inflection AI a few weeks ago, we promised we’d go back and see how its LLM Inflection-1 compares to the other large models that are vying to be the foundation of AI additions to ad applications big and small and here and there and everywhere. How all of this can be monetized remains to be seen, but if the costs of training and inference drop, as we think, it’s reasonable to assume that generative AI will be incorporated into almost everything.
Let’s talk scale and scope for a minute, and especially the metric and token counts used in LLM training. These two together drive the use of flops and the increasingly emerging behavior of models. And just like before during the data analytics era of the web, it seems like more data beats a better algorithm, but only up to a point with AI training because after a certain point, the data on the internet ( or mined from elsewhere) that can be chopped up into bits which is the token, and a token that’s about four characters long is complete and completely garbage and actually makes a model perform worse, not better.
Parameters in a neural network are weights on the connections between virtual neurons expressed in the code that are similar to the actual voltage spikes for neuron firing in our real brain. The act of training is to use a dataset to create these activations and then refine them by propagating the correct responses into the training so it can improve. With this method, by first using labeled datasets and then not requiring them at all once a certain scale of data and processing is possible, we can teach a neural network to slice any piece of data, such as an image or block of text , in bits and then reassemble them so it knows what that image or text is. The more parameters you have, the richer the spike dance on the neural network.
So tokens tell you how much you know, and metrics tell you how well you can think about what you know. Smaller parameter counts versus a larger set of tokens give you quicker, yet simpler answers. Counting larger parameters versus a smaller set of tokens gives you great answers on a small number of things. Finding a balance is key, and we think AI researchers are still trying to figure that out.
Let’s review the parameter and token counts on some of the models:
- Google’s BERT model, from 2018, came with 110 million (basic) and 340 million (large) parameter counts; the training dataset contained 3.3 billion words but we don’t know the token count. The average word size in English is 4.7 characters and the average token size is around four characters, which would bring the token count to around 4 billion tokens.
- The Nvidia Megatron MT-NLG variant of Google’s BERT model weighed 530 billion parameters, but was only trained on 270 billion tokens.
- Google’s Chinchilla model, which was used to find the best ratio of number of tokens to number of parameters for a given amount of computation, exceeds 70 billion parameters with a training set of 1.4 trillion tokens. Chinchilla’s rule of thumb, shown in this document, is 20 text tokens per parameter.
- Google’s Pathways Language Model (PaLM) was released in 2022 and chewed through 780 billion tokens and peaked at 540 billion parameters. The PaLM 2 model, which has been trained for more than 100 languages, came out in May with a peak of 340 billion parameters and 3.6 trillion tokens in its training dataset. PaLM 2 is what Google is rolling out to over 25 of its services.
- Google Gemini, short for Generalized Multimodal Intelligence Network, builds on the problem-solving capabilities of game model DeepMind AlphaGo and will be next in the search engine giant’s series of generative AI models. It’s aimed directly at OpenAIs GPT-4 and we have no idea what number of parameters or number of tokens it will have. It’s much easier to increase parameter counts and neural network layers than it is to increase the size of the training data, that’s for sure.
- The high-end of the third iteration of OpenAI’s Generative Pre-Trained Transformer (GPT-3) model, codenamed Davinci and released in early 2019 by OpenAI, was trained on approximately 499 billion tokens and peaked at 175 billion parameters. The model has been refined in GPT-3.5 with new algorithms and protections.
- GPT-4 came out in March this year and is said to have at least 1 trillion parameters and some have estimated it to have around 1.76 trillion parameters. This is a factor of 10 times more parameters. While OpenAI didn’t say how much data it chewed, we think OpenAI will hit the 3.6 trillion range like Google in more than a hundred languages, and the English corpus won’t change much, even with two more years of Internet content added. . (GPT-4 will discontinue in September 2021.) GPT-5 will likely be what OpenAI slams into all those languages.
- The LLaMA model released this year by Meta Platforms was trained using 6.7 billion, 13 billion, 32 billion and 65.2 billion parameters, with the two smallest models using 1 trillion tokens and the two largest using 1.4 trillion tokens.
With that as context, let’s talk about the basic Inflexion-1 model. First of all, the details of the architecture in terms of number of parameters and data tokens used for training are secret. Which is not cool and is done on purpose, as the Inflection-1 performance paper published by Inflection AI openly admits. Well, that’s not funny. But if Inflection AI is paying attention like Meta Platforms is doing, then the metric count might be mediocre while the token count might be quite high. We strongly suspect that somewhere around you guessed 1.4 trillion tokens. Heaven only knows where the parameter count for Inflection-1 is.
When Inflection AI talks about generative AI models, it divides the world into two camps. Those that have implemented as much or more floating point computation as Google’s PaLM model and those that haven’t. Inflection AI falls into the latter category, alongside GPT-3.5 and LLaMA, among others, and performs nearly as well as PaLM-2 and GPT-4 in many tests.
Now let’s talk about the data. Here’s how Inflection-1 stacked up against GPT-3.5 and LLaMA on a variety of tasks:


While this graph is nice and all, what you need to know is the precise configurations of the clusters that ran these tests to figure out which one performs best with what precision. This is something we need to consider, just as we would a very fast but buggy processor in an HPC cluster. AI systems can get something wrong, and they will, and who cares if they get an answer wrong faster? And hopefully not burning a ton of money doing it. . . .
What this graph shows is whether or not you’re color-challenged (we are), but it also shows that on a variety of exam and question-and-answer tasks, Inflection 1 can stand its toe with the 175 billion GPT metric -3.5 and LLaMAs 65 billion parameter models.
The paper has many comparisons, and we won’t go through them all, but this one about model accuracy on the Multitasking Language Understanding (MMLU) Benchmark Suite is interesting because it brings many together:
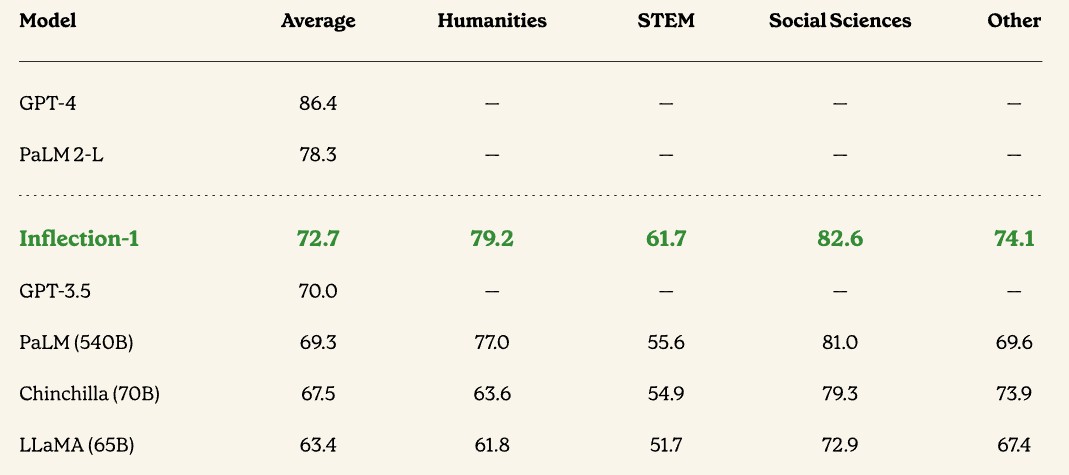

In all cases, Inflection-1 LLM does better than GPT-3.5, PaLM, Chinchilla and LLaMA, although it has a long way to go before it can catch PaLM 2-L and GPT-4. If these first three models are training on essentially the same dataset of 1.4 trillion tokens (which none of them own, by the way), the only thing Inflection AI can do is ramp up the metric count and modify its model to reach Microsoft /OpenAI and Google. Those extra parameters eat up memory and cause a model to take longer to train, and it might not be worth it for the Pi service Inflexion AI offers.
What we can expect is that Generative AI models will be scaled not by accuracy in the purest sense, but by good enough accuracy for the service being sold. An online chatbot friend for loners doesn’t need the same accuracy as an AI that is actually making decisions or offloading any responsibility from a decision to humans leaning on the AI to help them make decisions.
#balance #training #generative
Image Source : www.nextplatform.com