


Large language models (LLMs) have come a long way recently, demonstrating extraordinary performance in conversational tasks that require natural language processing. Examples include the commercial products ChatGPT, Claude, Bard, text-only GPT-4, and the opensource community LLama, Alpaca, Vicuna, ChatGLM, MOSS, etc. artificial intelligence models. As a result of the LLM’s effectiveness, the multimodal modeling community is forging a new technology path to use LLM as a universal interface to create generic models, where the feature space of a given job is tailored to be in line with the feature space of pre-trained language models.
Vision and language models, such as MiniGPT-4, LLaVA, LLaMA-Adapter, InstructBLIP, etc., align the vision encoder to LLM by adjusting the instructions on image-text pairings as one of the representative tasks. The quality of the alignment significantly affects the performance of vision and language models within the statement optimization design concept. While these jobs have excellent multimodal capabilities, their region-level alignment prevents them from progressing beyond more complex comprehension tasks such as region captioning and reasoning. Their alignments are exclusively on image-text pairings. Some studies use external vision models such as MM-REACT, InternGPT, and DetGPT to provide regional-level insight into visual language patterns.
Their non-end-to-end design, however, might be better for all-purpose multimode models. This work aims to develop an end-to-end visual language model that provides a detailed understanding of the region of interest. The main design of image-level visual language models is to establish the object box as a spatial instruction format as the model architecture in these models compresses the whole image like image embedding without any operation to do reference to particular parts. To get the answer, LLM is provided with the visuals culled from spatial teaching and language instruction. For example, the model will replace with the feature of the area referenced by the spatial statement when the survey is the interleaved sequence of What are you doing?
RoIAlign or Deformable focus are two flexible implementation methods for spatial education. They update training data from image-text datasets to region-text datasets, where each element’s bounding box and text description are provided to create fine-grained alignment between region-text pairs. Publicly accessible datasets, such as COCO object identification, RefCOCO, RefCOCO+, RefCOCOg, Flickr30K entities, Visual Genome (VG), and Visual Commonsense Reasoning (VCR), are combined. These datasets are modified into a format for instruction tweaking. Furthermore, by using commercially available object detectors to extract object boxes from images and use them as spatial instruction, standard object detectors can be used to leverage image-to-text training data, such as LLaVA150K, for spatial teaching. Their model is improved in It is used to pre-train the region feature extractor without impacting the LLM.
Their model has improved conversation quality and generates more human-like responses as a result of learning from these image-text datasets that have been carefully selected for editing visual prompts. According to the length of the text, the collected datasets are divided into two types. First, the short text data includes information about item categories and basic characteristics. Without affecting the LLM, it is used to pre-train the region feature extractor. Second, longer texts often include complicated ideas or require logical thinking. They provide complex spatial instructions for this data to enable end-to-end LLM and area feature extractor tuning, simulating flexible user instructions in real-world use. Their approach, which takes advantage of the fine-tuning of spatial instructions, offers the user viewing-language models a unique interactive experience where the user can communicate the request to the model in both linguistic and spatial instruction form .
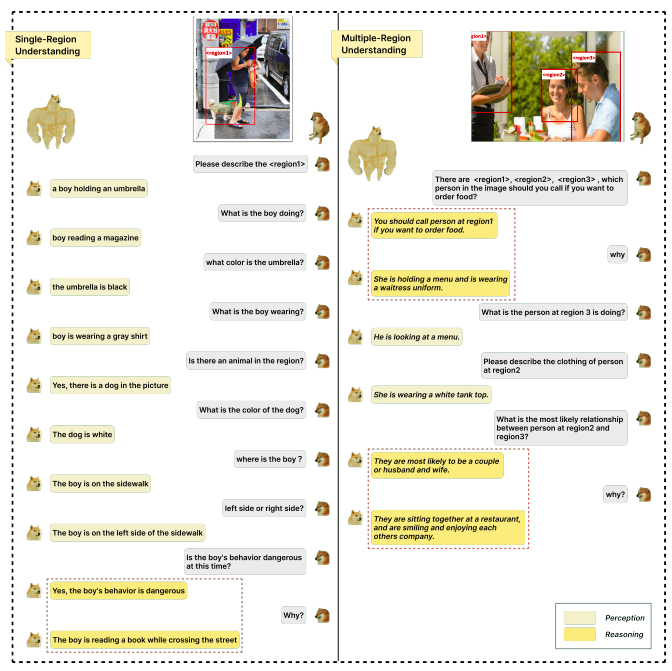
Figure 1 illustrates how this translates into new skills that go beyond image-level understanding, such as complicated area reasoning and region captioning. In conclusion, their work contributes the following:
By providing LLM training on regional text datasets, they advance visual language patterns regionally. Their model was built with additional features, such as region captioning and reasoning, compared to previous image-level models.
To get an answer, they introduce the spatial instruction to refer to the region of interest and the features of the region retrieved from the visual encoder are provided to the LLM along with the language instruction.
The coding, dataset instruction optimization format, and online demo are all available on GitHub.
Check out thePaperANDGithub link.Don’t forget to subscribeour 26k+ ML SubReddit,Discord channel,ANDEmail newsletterwhere we share the latest news on AI research, cool AI projects, and more. If you have any questions regarding the above article or if you have missed anything, please do not hesitate to email us atAsif@marktechpost.com
Check out 100s AI Tools in the AI Tools Club


Aneesh Tickoo is a Consulting Intern at MarktechPost. She is currently pursuing her BA in Data Science and Artificial Intelligence from Indian Institute of Technology (IIT), Bhilai. She spends most of her time working on projects that harness the power of machine learning. Her research interest is image processing and she is passionate about building solutions around it. She loves connecting with people and collaborating on interesting projects.
#Research #Introduces #GPT4RoI #Visual #Language #Model #Based #Instruction #Large #Language #Model #LLM #Optimization #RegionText #Pairs
Image Source : www.marktechpost.com