


For various downstream tasks, including language and code translation, compositional thinking, and fundamental arithmetic operations, large language models such as GPT-3/4, PaLM, and LaMDA exhibited general characteristics, sometimes emergent abilities. Perhaps surprisingly, the model’s training goal, which is often an autoregressive loss based on predicting the next token, doesn’t directly encode these goals. These abilities have been explored in depth in previous studies, along with how they change based on the scale of the training computation, data type, and model size. However, given the complexity of the data and the range of jobs assessed, it is still difficult to separate the elements. They went out to identify the top contributors accelerating the emergence of these talents because they were curious about the factors driving these abilities in next token predictors.
These factors include data format and size, model size, existence of pre-training, and hinting style. Their work is carried out in a controlled environment to allow for a more in-depth analysis of these parameters. They focus on teaching tiny transformer models, including NanoGPT and GPT-2, math when trained by random init. They employ the common autoregressive prediction loss of the next token, going from a model with 10.6 million parameters to one with 124 million. UW Madison researchers aim to understand how these models can actually learn fundamental math operations such as addition, subtraction, multiplication, square root and sine, giving us a deeper perspective on how emerging talent is sparked. They have outlined their conclusions below.
- Sample size and data format are both important.
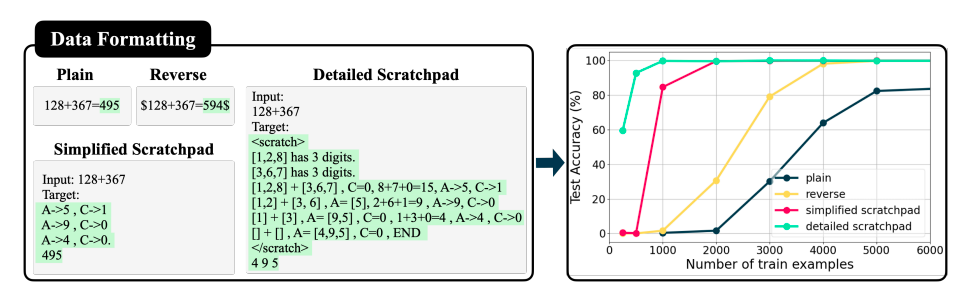
First, they note that teaching a model addition using typical addition samples, such as A3A2A1 + B3B1B1 = C3C2C1, is not ideal since it forces the model to first evaluate the most significant digit C3 of the result, which depends on all the figures of the two summarized together. They allow the model to learn a simpler function by training it on samples with inverted results, such as A3A2A1 + B3B1B1 = C1C2C3, which greatly increases the complexity of the sample. A further learning enhancement is a balanced sample of many variations of addition, depending on the digits and carry involved. They see sharp shifts from 0% to 100% accuracy as a function of the amount of training data, even in this simple scenario. Unexpectedly, they note that completing a low-ranking matrix is similar to learning an n-digit addition map from random samples. They can provide a rationale for such phase changes thanks to this connection.
- Data on cognitive flow during training.
Based on these findings, they examine the possible benefits of chain-of-thought data during training. This format allows the model to learn the distinct elements of difficult tasks as it includes step-by-step operations and intermediate outputs. This structure is taken directly from the relevant literature, such as eg. According to the CoT tuning literature, they found that CoTtype training data greatly improved learning in terms of sample complexity and accuracy; however, their results remain valid even in the absence of language pre-training. They hypothesize that this is because the model can learn a higher-dimensional but simpler function map by decomposing the necessary compositional function to be realized into individual components. They provide examples of each of the four data formatting techniques they examined in their research in Figure 1.
- Training with blends of text and math.
Because LLMs are trained on huge volumes of data downloaded from the internet, where it is difficult to cleanly separate various forms of data, they also examine how text and numerical data interact during training. They track how the proportion of text to arithmetic input affects the perplexity and accuracy of models. They find that knowing the arithmetic operations discussed above can improve the performance of each task individually, and that switching from zero-shot to one-shot hinting significantly increases accuracy. However, accuracy is less noticeable when more examples are given. the importance of model size and pre-training.
- Role of pre-training and model scale.
Furthermore, they examine the function of pretraining by refining models such as GPT-2 and GPT-3 and find that while zero-shot performance on arithmetic operations is poor, the previous skills developed during pretraining allow for acceptable performance on some fundamental arithmetic tasks, even with a limited number of fine-tuning samples. However, when the model is pre-trained on operations with standard formatting, optimizing non-standard formatting, such as reverse formatting, can interfere with model performance and reduce accuracy. Finally, they research how scaling affects arithmetic performance and find that although scaling helps in learning arithmetic operations, it is not a prerequisite.
- Length and compositional generalization.
One might wonder if their trained models have a solid understanding of mathematics. Their research offers a complex answer. They find it difficult to generalize the length beyond the length of the training digits. For example, a model has difficulty adjusting and correctly calculating this missing digit length if it is trained on all n digit lengths but excludes one particular length. As a result, the models perform well within the training digit length range, but much worse outside of it. This demonstrates that models learn arithmetic more as a mapping function confined to taught digit lengths rather than a flexible procedure. This is beyond rote memorization, but falls short of a thorough understanding of math.
- New from previous efforts.
They do not claim that their method is original in the type of training data they use, but rather that it draws heavily on previous work using training data to improve model performance. Greater emphasis on randomly initialized models and extensive ablation investigations of various sample/data formats and model scale settings to separate variables leading to the rapid formation of arithmetic skills distinguish their work from other research in the field. Furthermore, some of the events they detect have some direct but potentially illuminating theoretical explanations in their study.

Check out thePaper AND Github link.Don’t forget to subscribeour 26k+ ML SubReddit,Discord channel,ANDEmail newsletterwhere we share the latest news on AI research, cool AI projects, and more. If you have any questions regarding the above article or if you have missed anything, please do not hesitate to email us atAsif@marktechpost.com
Check out 100s AI Tools in the AI Tools Club


Aneesh Tickoo is a Consulting Intern at MarktechPost. She is currently pursuing her BA in Data Science and Artificial Intelligence from Indian Institute of Technology (IIT), Bhilai. She spends most of her time working on projects that harness the power of machine learning. Her research interest is image processing and she is passionate about building solutions around it. She loves connecting with people and collaborating on interesting projects.
#study #University #Wisconsin #investigates #small #transformers #trained #random #initialization #efficiently #learn #arithmetic #operations #token #prediction #goal
Image Source : www.marktechpost.com